[논문리뷰] SAM(Segment Anything)

이번에 제가 소개할 논문은 Meta AI 가 발표한 SAM입니다.


객체 탐지는 객체의 위치를 찾고 그 객체가 무엇인지 분류(Classification)하는 작업입니다.
화면에 보시는 타임라인은, 2001년부터 최근까지 객체 탐지 기술이 어떻게 발전해왔는지를 보여줍니다.
2012년 ALEXNET을 기점으로 전통적인 방식에서 딥러닝 기반 탐지 방식으로 전환되고,
2014년엔 2 stage detector 의 대표적인 모델 RCNN이 등장하고,
2016년엔 one stage detector의 대표 모델 yolo가 등장합니다.
그리고 2020년에는 transformer 를 객체 탐지에 최초로 적용한 detr이 등장합니다.

이제, SAM의 등장배경을 알아보겠습니다
NLP에서는 GPT가 한 줄 프롬프트만으로 번역·요약·코딩까지 다 해주는데, 컴퓨터 비전은 아직 gpt와 같은 모델이 없습니다. 이를 해결하려는 시도가 바로 SAM입니다.
이전 모델들은 작업별 모델 구조가 다르기에 사용자가 매번 task에 맞는 모델을 새로 학습하거나 바꿔야 해서 범용성이 없었고, 프롬프트 입력을 미지원하고 고정된 입력된 방식만 지원해서 상호작용이 불가능 하였고, 대부분은 특정 데이터셋에서 훈련된 후, 다른 도메인에서 사용 시 재학습이 필요하였기에 zero-shot 사용이 불가하고, 대규모 학습 데이터가 부족하다는 한계가 있었습니다.
SAM은 이와 다르게 image segmentation 분야의 혁신적인 모델로(segmentation이 픽셀단위로 윤곽선을 그린 것을 의미합니다), 프롬프트 기반 실시간 분할을 가능하게 하며, 새로운 객체나 이미지에 대해서도 추가 학습 없이 zero-shot 일반화를 수행할 수 있습니다.

아까 말했듯이 SAM은 CV에서도 다양한 태스크에 활용될 수 있는 범용적인 segmentation foundation model을 설계하고자 했습니다.
이를 위해 먼저 생각해야 했던건 왜 CV에는 아직 GPT 같은 모델이 없는가? 였습니다. 즉, 어떤 문제들이 이를 막고 있었는가 였습니다.
첫번째는 prompt engineering니다.
NLP는 간단한 텍스트 프롬프트만으로 다양한 작업을 수행할 수 있는데요, CV는 그렇지 않습니다.
포인트, 박스, 마스크등 입력 방식도 제각각이고, 이를 유연하게 처리할 수 있는 구조가 부족했습니다.
두번째는 데이터 문제입니다.
NLP는 웹에 존재하는 방대한 텍스트로 학습할 수 있지만,CV 특히 segmentation 분야는
정밀한 마스크 데이터가 필요해서 대규모 학습 자체가 어렵고 비쌉니다.
이 외에도 CV는 task마다 모델 구조가 달라 범용화가 어려운 점 등 다양한 기술적 제약이 존재합니다.
이러한 문제들을 해결하기 위해 promptable 모델을 설계하고, 이를 대규모 데이터셋을 통해 사전학습(pretraining)함으로써
다양한 분할 작업을 하나의 모델로 해결할 수 있도록 하였습니다.
이를 위해 SAM은 충분히 보편적인 task 정의, 다양한 프롬프트 입력에 유연하게 대응할 수 있는 model 구조,
이를 학습시킬 수 있는 거대한 원천 데이터 ,크게 세 가지 요소를 기반으로 설계됩니다.
그리고 이렇게 논문에서는 이렇게 3개의 질문을 던지면서 시작합니다.

아까 보셨던 질문들을 하나씩하나씩 보면서 sam에 대해 알아보도록 하겠습니다
이 질문에 대한 답은 promptable segmentation Task입니다. 이는 이미지와 어떤 "prompt"가 주어졌을 때 "유효한 Mask"를 반환하는 작업입니다.
여기서 prompt는 이미지에서 분할할 대상을 지정하는 것 이고, Points, BBox, Mask, 심지어는 Text가 될 수도 있습니다.
valid한 segmentation task 는 모호한 prompt가 주어졌을 때도 합리적인 mask를 출력해야 한다는 것을 의미합니다.
또 앞과 같은 task를 달성하기 위해서는 사전 학습이 이루어 져야 합니다.

이제 앞의 모든 학습을 가능하게 하는 핵심 자원인 데이터(data)에 대해 설명해보도록 하겠습니다.
SAM은 대규모 프롬프트 기반 segmentation 학습을 위해11억 개의 마스크 데이터를 포함한
SA-1B 라는 거대한 데이터셋을 사용합니다.
이 SA-1B를 만들기 위해 Meta는 자체적인 데이터 엔진(data engine)을 설계했습니다.
데이터 엔진은 3단계로 구성되어 있는데, 1,2 단계는 사람과 AI가 함께작업하고 3단계는 완전히 AI만으로 자동 생성됩니다.
학습은 이와 같은 절차로 진행됩니다.
먼저, 각 학습 샘플에 대해 다양한 프롬프트의 시퀀스(예: points, boxes, masks)를 시뮬레이션하여 생성합니다.
이후, 주어진 프롬프트에 대해 모델이 예측한 마스크(predicted mask)를 실제 정답인 ground truth mask와
비교하면서 학습이 이루어집니다.
이러한 접근은 기존의 interactive segmentation 방식에서 아이디어를 가져왔고,
이는 사람이 green point(선택할 부분), red point(선택하지 않을 부분) 등을 클릭하면서 CNN 모델을 훈련시켜,
충분한 사용자 입력 후에 올바른 마스크를 점진적으로 얻는 방식입니다.
하지만 SAM의 pre-training은 여기서 한 단계 더 나아가
한 번의 prompt만으로도 항상 유효한(valid) 마스크를 예측을 하고자 해서, SAM에 특화된 모델 구조(specialized modeling)와 학습 손실 함수(training loss choices)가 필요한데, 이는 뒤에서 설명드리겠습니다.

이제 앞의 모든 학습을 가능하게 하는 핵심 자원인 데이터(data)에 대해 설명해보도록 하겠습니다.
SAM은 대규모 프롬프트 기반 segmentation 학습을 위해11억 개의 마스크 데이터를 포함한
SA-1B라는 거대한 데이터셋을 사용합니다.
이 SA-1B를 만들기 위해 Meta는 자체적인 데이터 엔진(data engine)을 설계했습니다. 데이터 엔진은 3단계로 구성되어 있는데, 1,2 단계는 사람과 AI가 함께작업하고 3단계는 완전히 AI만으로 자동 생성됩니다.

이 단계에서는 먼저 공개 데이터셋으로 SAM을 초기 학습시키고,
이후 annoctator가 SAM의 예측 결과를 수정·보완하면서 약 4.3M(430만)개의 마스크를 만들어 점진적인 모델 개선에 활용했습니다.
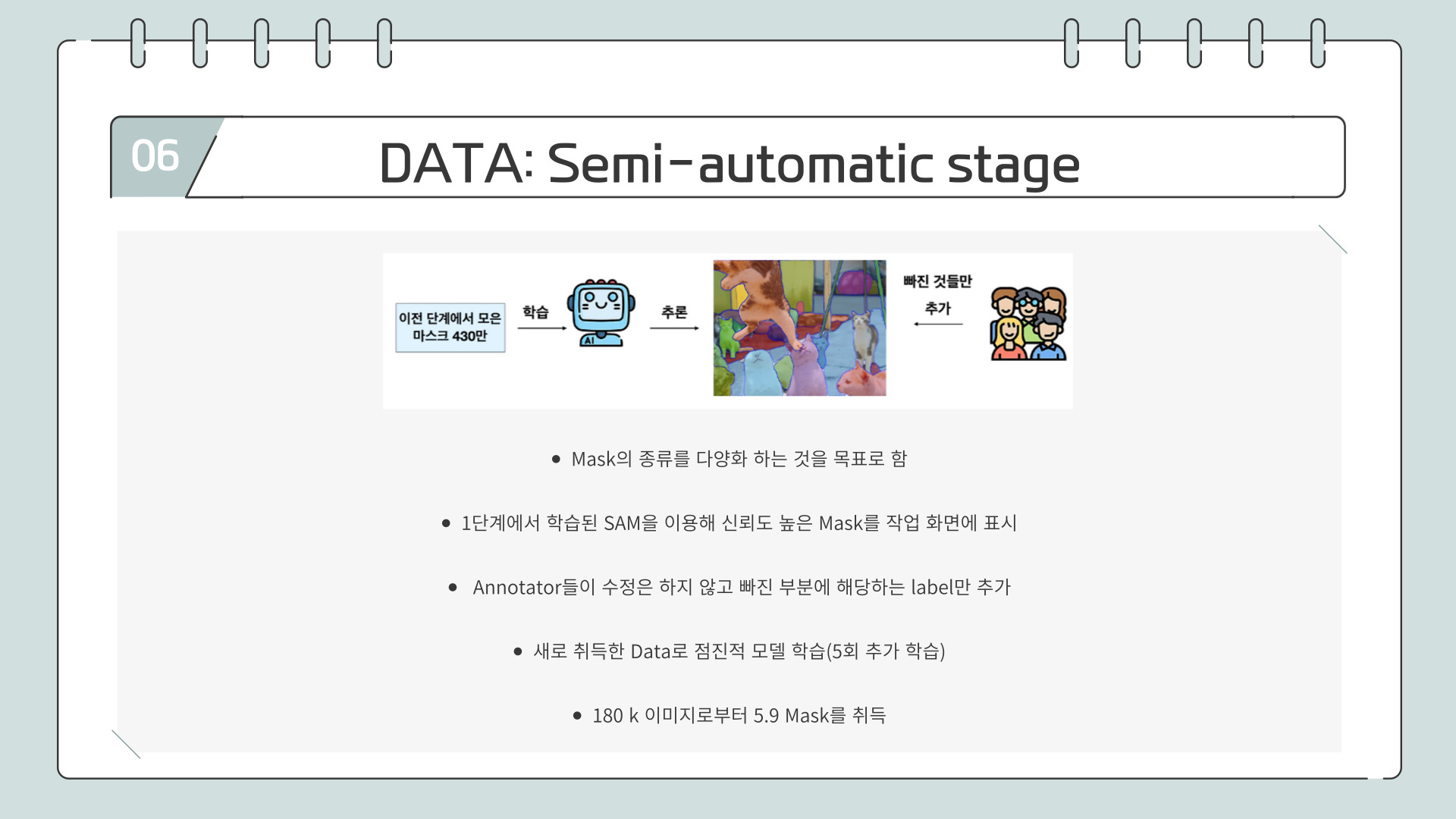
Semi-automatic 단계에서는 1단계에서 학습된 SAM을 활용해 신뢰도 높은 마스크를 자동 생성하고, 사람이 직접 수정하지 않고 누락된 객체에 대해서만 label을 추가 하여 총 18k 590만 개의 마스크를 수집했습니다.

Fully automatic 단계에서는 사람이 개입하지 않고, SAM이 완전히 자동으로 마스크를 생성하며,
IOU 기준으로 신뢰도 높은 마스크만 남기고 중복 제거 등의 후처리를 거쳐, 1,100만 장의 이미지로부터 11억 개의 마스크를 수집했습니다.
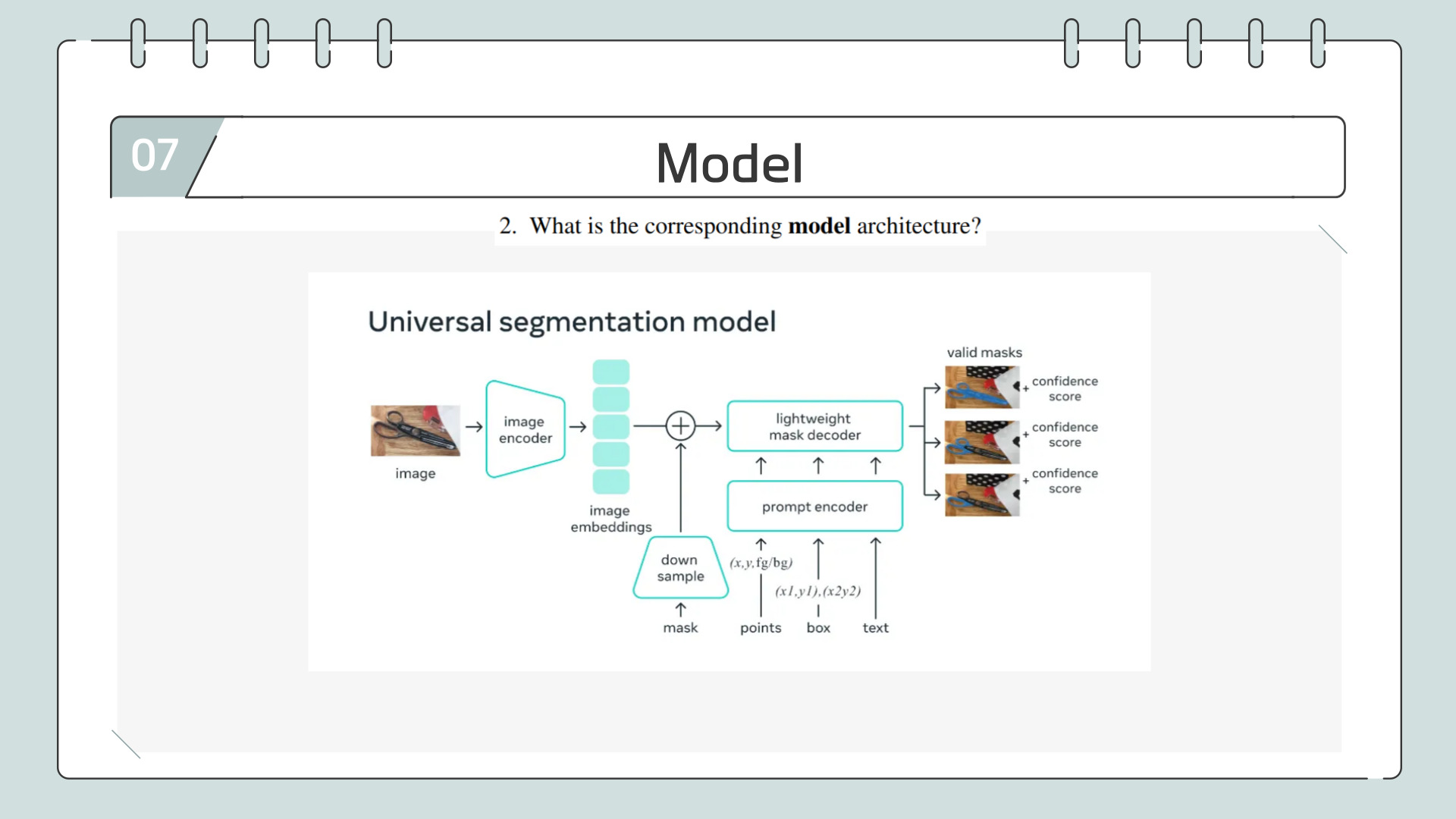
모델 구조는 이렇게 생겼고 뒤에서 구체적으로 설명드리겠습니다.

SAM의 이미지 인코더는 MAE로 사전학습된 비주얼 트랜스포머입니다.
여기서 MAE, Masked AutoEncoder는 입력 이미지의 일부 패치를 무작위로 가려 놓고,
나머지 정보만으로 복원하도록 학습합니다. 이 방식 덕분에 데이터 효율이 높고, 대규모 사전학습에서도 성능이 강력해집니다.
MAE의 기반이 되는 ViT ― Vision Transformer는 이미지를 일정 크기의 패치로 쪼개 토큰처럼 처리해 Transformer에 넣는 구조입니다.

Prompt Encoder는 사용자가 입력한 점·박스·텍스트·마스크를 모두학습 가능한 토큰 임베딩으로 변환합니다. 점·박스·텍스트 같은 sparse 프롬프트는 위치·문맥 정보를 부여해 토큰화하고, 실제 마스크를 주는 dense 프롬프트는 별도 CNN으로 압축해 이미지 임베딩과 합칩니다.

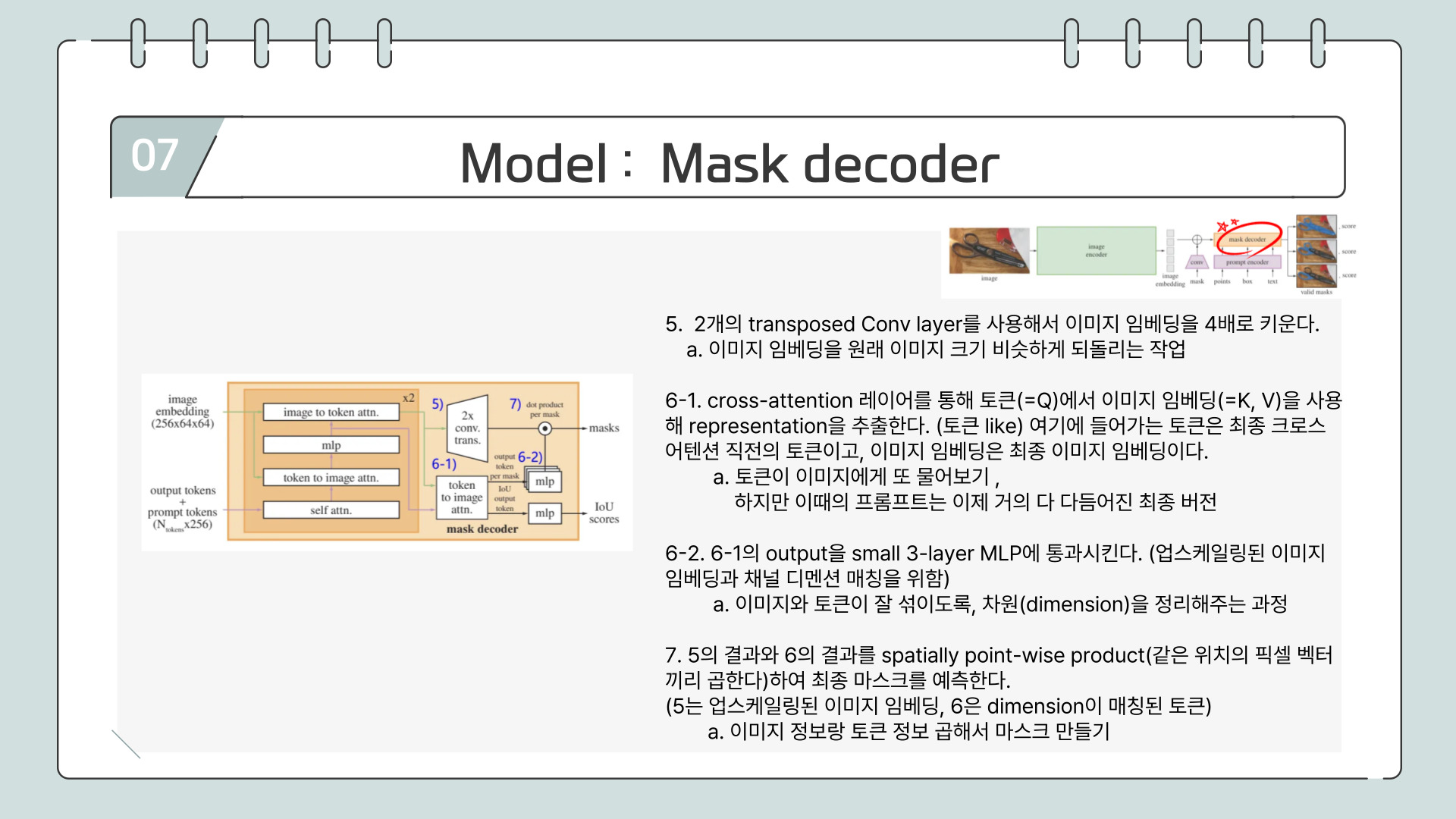
mask encoder는 위의 ppt두장을 살펴보시면 됩니다.

이 부분도 ppt를 참고해 주세요.

SAM은 마스크 예측을 위해 Focal Loss와 Dice Loss를 사용하며, 이 두 손실을 20:1 비율로 가중 합산합니다.
- Focal Loss는 예측이 어려운 픽셀에 더 큰 가중치를 줘서 복잡한 경계나 희미한 객체에 집중하게 합니다.
- Dice Loss는 예측 마스크와 실제 마스크의 겹치는 정도를 측정하며, 작은 객체나 경계에 민감하게 작동합니다.
이렇게 두 손실을 함께 사용해 정확하고 세밀한 마스크 예측이 가능해집니다.
Training Algorithm
→ 앞에서 interactive segmentation에서 아이디어를 얻어서 발전한다고 했는데, 기존 모델은 사람이 반복적으로 도와주는 시스템이였지만 SAM은 그 과정을 스스로 시뮬레이션해서 한 번에 잘 예측하는 모델을 만들었다는 점만 짚고 넘어가겠습니다.

다양한 태스크에서 SAM이 기존 기법과 어떻게 비교되는지 5가지 실험 결과를 통해 확인해 보겠습니다
SINGLE POINT VALID MASK EVALUATION
point 하나만 정보로 주었을 때 object의 mask를 얼마나 잘 생성해내는지에 대한 task이다. 그래프에서 보면 70% 이상의 데이터셋에서 SAM이 좋은 성능을 보이고 ambiguity 특성까지 고려하였을 때는 (주황색 점선) SAM이 모든 데이터셋에서 높은 성능을 보여준다.
ZERO-SHOT EDGE DETECTION
object들의 edge(윤곽선)를 검출해내는 task이다. Soble filter와 Canny 같은 고전 computer vision 방식의 detector보다는 높은 성능을 보여주지만 딥러닝 기반의 다른 방법보다는 성능이 낮다. 다만, 그 차이가 크지 않습니다.
OBJECT PROPOSAL
Object Proposal은 객체가 있을 법한 영역을 예측하는 task를 말하고, RCNN과 같은 object detection 모델에서 사용되는 개념이다.
이것도 마찬가지로 어느 정도 잘 한다는 것을 의의로 두고 있습니다.

ZERO-SHOT INSTANCE SEGMENTATION
앞에서 object detection후 해당 object를 segmentation한 것.
기존의 모델(ViTDet-H)보다 약간 낮은 성능
ZERO-SHOT TEXT-TO-MASK
Text만을 입력으로 받고 해당 text에 맞는 부분의 segmentation mask를 만들어내는 task이다. text만 주었을 때는 잘 되지 않고, 추가 point를 주었을 때 어느 정도 되는 것을 볼 수 있습니다


논문
https://arxiv.org/abs/2304.02643
Segment Anything
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M license
arxiv.org
참고한 자료
https://davidlds.tistory.com/29
[논문 리뷰] SAM(Segment Anything) 요약, 코드, 구현
논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다. 나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다. SAM(Segment Anything) Segment Aything KIRILLOV, Alexander, et al. Segment anything. ar
davidlds.tistory.com
https://www.youtube.com/watch?v=HSBb9ImSohA&t=4153s
https://www.youtube.com/watch?v=gSUpUiqXB6c